
OLAP
1.介绍
OLAP(On-Line Analytical Processing),译为联机分析处理,权威的定义为:OLAP是使分析人员、管理人员或执行人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映企业维特性的信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。
目前数据处理大致可以分为两大类:OLAP和OLTP(On-Line Transaction Processing,联机事务处理)。OLTP的出现早于OLAP。
OLTP是传统数据库的主要应用,面向当前的数据,主要是基本的、日常的事务处理。随着数据库技术的广泛应用,企业产生了大量的数据。企业管理人员迫切需要从这些大规模数据中挖掘潜在的商业信息,从而更好的做出决策。然而OLTP在对大规模数据进行分析处理时的表现一直差强人意。在这种情况下,数据仓库和OLAP技术应运而生。
数据仓库将多种数据源中的数据,根据不同的主题进行存储,并对原始数据进行抽取、转换和装载等一些筛选和清晰工作。数据仓库保存历史数据,支持数据分析。OLAP将数据仓库中的数据通过多个角度和层次进行展现,是决策分析人员更好的理解历史数据。OLAP的目标是满足决策支持或多维环境特定的查询和报表需求,它的技术核心是“维”这个概念,因此OLAP也可以说是多维数据分析工具的集合。
2.OLTP VS. OLAP
下表列出了OLTP和OLAP的对比:
| - | OLTP(数据库) | OLAP(数据仓库) |
|---|---|---|
| 用户 | 操作人员,低层管理人员 | 决策人员,高级管理人员 |
| 功能 | 日常操作处理 | 分析决策 |
| 模型 | ER模型 | 星型模型、雪花模型 |
| DB 设计 | 面向应用 | 面向主题 |
| 数据 | 当前的, 最新的细节的,二维的分立的 | 历史的, 聚集的, 多维的集成的, 统一的 |
| 存取 | 读/写数十条记录 | 读上百万条记录 |
| 工作单位 | 简单的事务 | 复杂的查询 |
| 用户数 | 上千个 | 上百个 |
| DB 大小 | 100MB-GB | 100GB-TB |
| 关注点 | 强调性能 | 强调灵活性 |
3.基本概念
3.1 维
### 3.1.1 维的定义
“维”人们观察数据的特定角度,是考虑问题时的一类属性,属性集合构成一个维(时间维、地理维等)。可以将其理解维数据仓库中描述数据的坐标轴。我们可以按某一个维对数据进行汇总,例如对公司的销售数据按照地理维进行汇总,从而计算出每个城市或省份的销售额。
3.1.2 维的层级
人们观察数据的某个特定角度(即某个维)还可以存在细节程度不同的各个描述方面,称为维的层级。例如对于“地理维”,其层级包括街道、城市、省份、国家等。对于地理维,我们可以选择按照街道汇总数据,也可以按照省份进行汇总数据,不同之处在于汇总的粒度不同。
3.2 度量
度量是对事件或事实的定量描述,可以是离散取值,也可以是连续取值,常用的度量包括:销售额、通话市场、购买次数等等。
4.基本操作
OLAP包括四种基本的操作:上卷、下钻、切片与切块、旋转,下面对这四种操作进行介绍。
4.1 上卷
简单来说,上卷是指对数据按照某一维度进行汇总,对选定的维度可以进行两种操作“改变维度层级”或者“消维”,即实现上卷有两种方式:
- 针对选定的维度,将数据从该维度的低级层次汇总到高级层次
- 消除维度
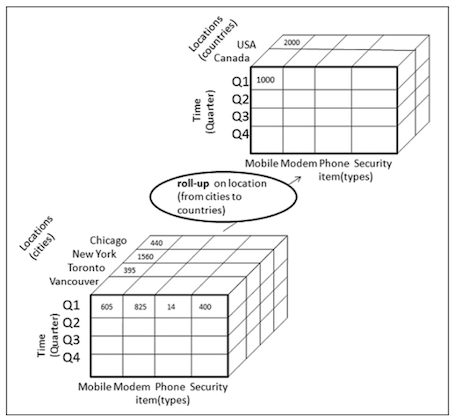
上图是数据上卷的一个例子,图中使用了第一种上卷方式。图中利用数据立方体来展示数据,立方体的坐标轴代表维。
假定描述的是销售数据,则图中下面的立方体描述的是(时间-季度,产品,地理-城市)粒度上的销售数据,面的立方体描述的是(时间-季度,产品,地理-国家)粒度上的销售数据。地理维从“城市”层次变为“国家”层级,数据发生了汇总。
如果根据图中下面的立方体,计算(时间-季度,产品)粒度上的汇总数据,则“地理维”被消除了,这就是第二种上卷方式。
4.2 下钻
下钻是上卷的逆过程,目的是分析汇总数据产生的具体原因。
与上卷的两种实现方式相对应,下钻的实现方式为:
- 针对选定的维度,将数据从该维度的高级层次具体到低级层次
- 增加维度
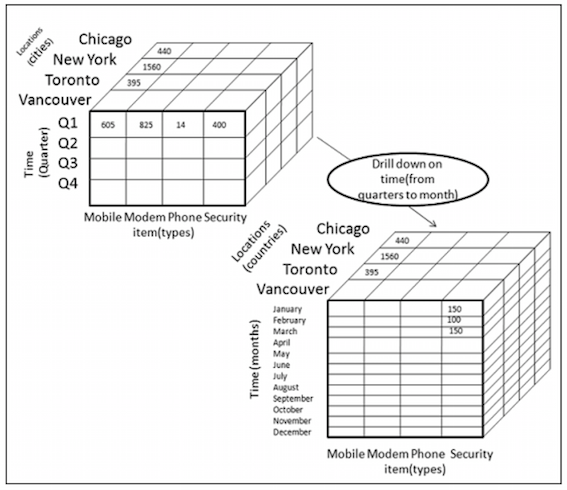
下图展示了下钻的过程,使用了第一种下钻方式。
4.3 切片与切块
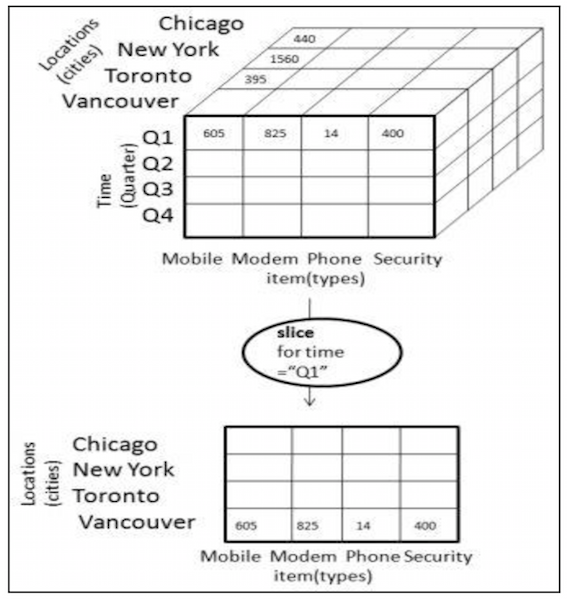
切片是指针对一个数据立方体,固定一个维度的取值并将数据从数据立方体中选出,形成子立方体,如下图所示。对于图中的数据立方体,限定时间维的取值为”Q1”,则得到切片后的数据。
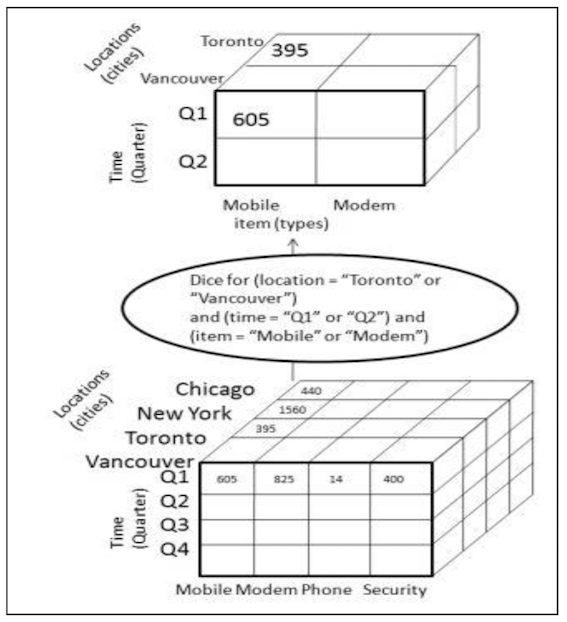
切块与切片类似,不同之处在于选择数据时选取两个或更多的维度,如下图所示
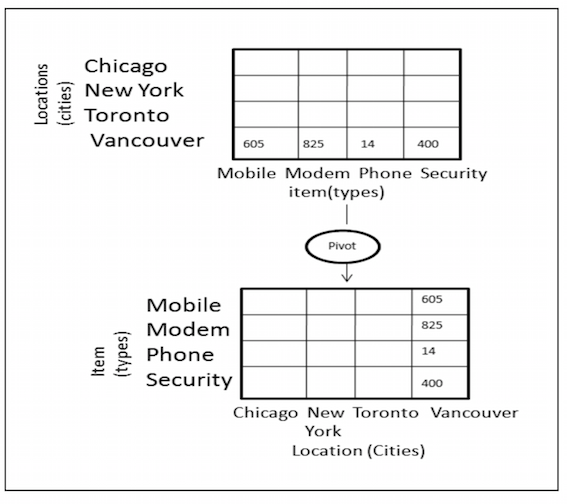
4.5 旋转
旋转就是改变维度的顺序,提供多种观测数据的方式,下图是数据旋转的例子。
5.基本分类
OLAP系统按照其存储器的数据存储格式可以分为关系OLAP(RelationalOLAP,简称ROLAP)、多维OLAP(MultidimensionalOLAP,简称MOLAP)和混合型OLAP(HybridOLAP,简称HOLAP)三种类型。
5.1 关系联机分析处理(ROLAP)
ROLAP将分析用的多维数据存储在关系数据库中并根据应用的需要有选择的定义一批实视图作为表也存储在关系数据库中。不必要将每一个SQL查询都作为实视图保存,只定义那些应用频率比较高、计算工作量比较大的查询作为实视图。对每个针对OLAP服务器的查询,优先利用已经计算好的实视图来生成查询结果以提高查询效率。同时用作ROLAP存储器的RDBMS也针对OLAP作相应的优化,比如并行存储、并行查询、并行数据管理、基于成本的查询优化、位图索引、SQL的OLAP扩展(cube,rollup)等等。
5.2 多维联机分析处理(MOLAP)
MOLAP将OLAP分析所用到的多维数据物理上存储为多维数组的形式,形成“立方体”的结构。维的属性值被映射成多维数组的下标值或下标的范围,而总结数据作为多维数组的值存储在数组的单元中。由于MOLAP采用了新的存储结构,从物理层实现起,因此又称为物理OLAP(PhysicalOLAP);而 ROLAP主要通过一些软件工具或中间软件实现,物理层仍采用关系数据库的存储结构,因此称为虚拟OLAP(VirtualOLAP)。
下表给出了ROLAP和MOLAP的异同:
| ROLAP | MOLAP |
|---|---|
| 沿用现有的关系数据库的技术 | 专为olap所设计 |
| 响应速度比molap慢:现有关系型数据库已经对olap做了很多优化,包括并行存储、并行查询、并行数据管理、基于成本的查询优化、位图索引、sql 的olap扩展(cube,rollup)等,性能有所提高 | 性能好、响应速度快 |
| 数据装载速度快 | 数据装载速度慢 |
| 存储空间耗费小,维数没有限制 | 需要进行预计算,可能导致数据爆炸,维数有限;无法支持维的动态变化 |
| 借用rdbms存储数据,没有文件大小限制 | 受操作系统平台中文件大小的限制,难以达到tb 级(只能10~20g) |
| 可以通过sql实现详细数据与概要数据的存储 | 缺乏数据模型和数据访问的标准 |
| 不支持有关预计算的读写操作:sql无法完成部分计算;无法完成多行的计算;无法完成维之间的计算 | 支持高性能的决策支持计算:复杂的跨维计算;多用户的读写操作;行级的计算 |
| 维护困难 | 管理简便 |
5.3 混合联机分析处理(HOLAP)
由于MOLAP和ROLAP有着各自的优点和缺点(如下表所示),且它们的结构迥然不同,这给分析人员设计OLAP结构提出了难题。为此一个新的OLAP 结构——混合型OLAP(HOLAP)被提出,它能把MOLAP和ROLAP两种结构的优点结合起来。迄今为止,对HOLAP还没有一个正式的定义。但很明显,HOLAP结构不应该是MOLAP与ROLAP结构的简单组合,而是这两种结构技术优点的有机结合,能满足用户各种复杂的分析请求。
参考资料
[1]. 联机分析处理 [2]. data warehousing